
PromptShark
Slash your LLM token costs with our prompt compression API
@ymultani7105
Details
- Follow on
- @PromptropyLinkedIn
- Categories
- AIDeveloper ToolsAutomation & Workflow
- Target Audience
- DevelopersFounders & CEOsStartups
- Platforms
- API
About PromptShark
PromptShark by Promptropy dynamically strips and reorders tokens in LLM inputs to reduce context length, drastically reducing inputs token costs and speeding up inference, all while retaining or even improving model response quality. Ideal for AI apps that have lengthy inputs(e.g. AI writing assistants) and GPT wrappers.
Screenshots
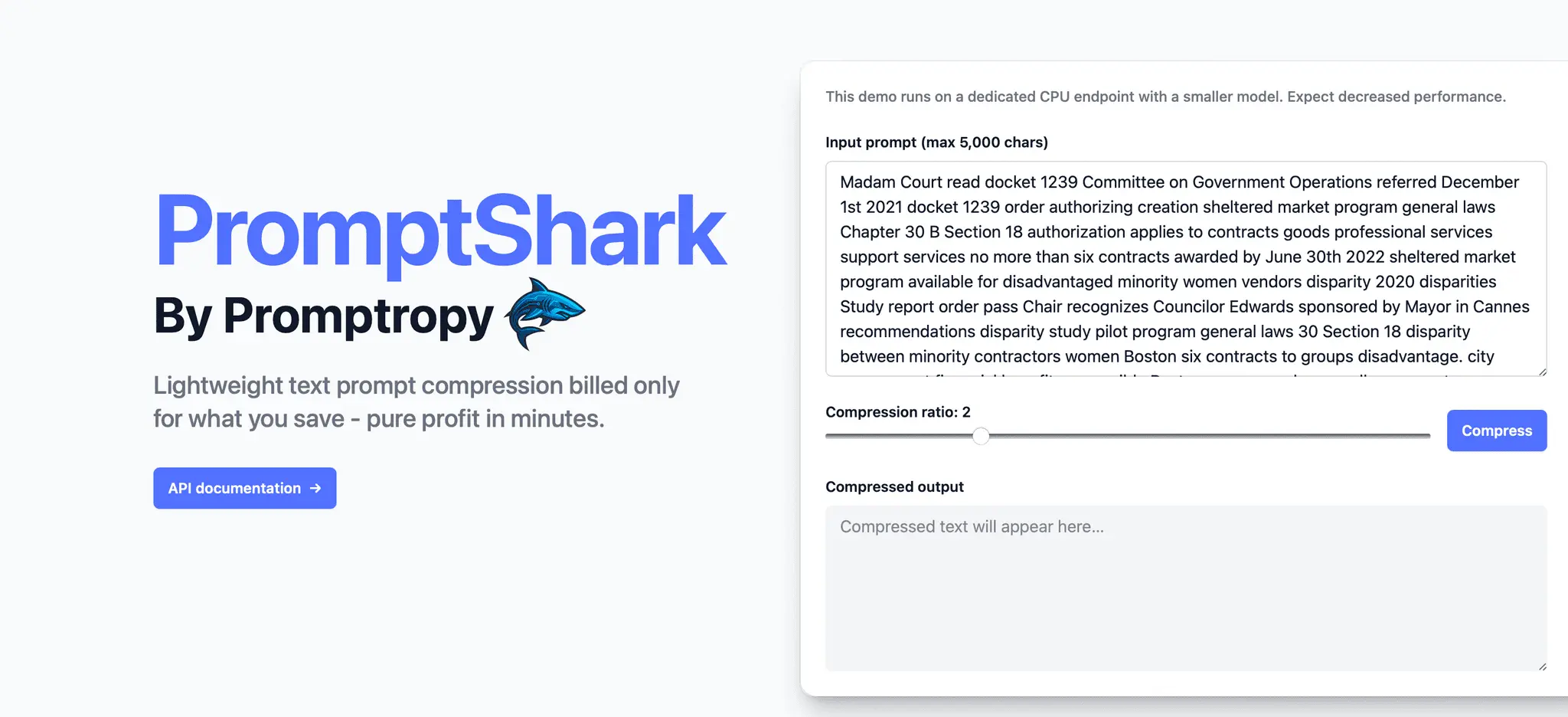


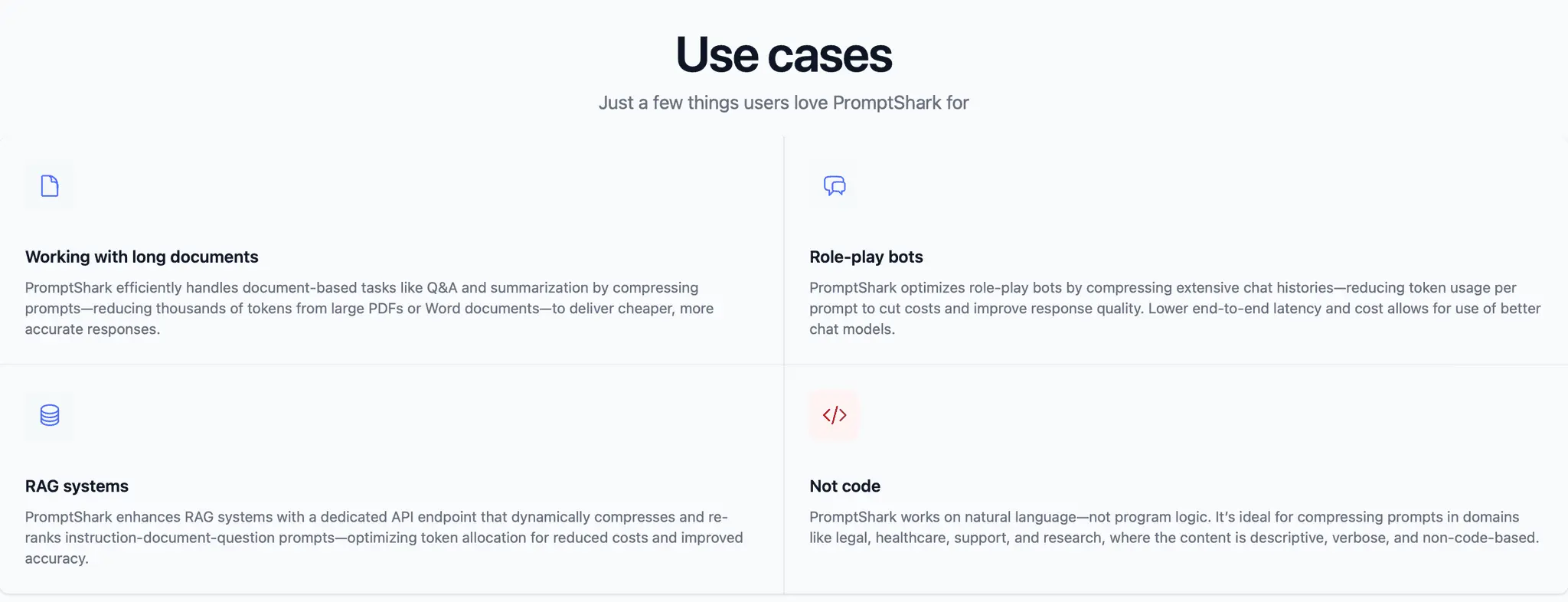
Reviews (0)
No reviews yet. Be the first to rate this product!
Comments (0)
No comments yet. Be the first to share your thoughts!